
La programmation dynamique est un principe mathématique pour optimiser des décisions qui sont prises en séquence après avoir observé l'état d'un système. Le principe peut être utilisé autant pour analyser un système asservis classique, comme contrôler la position d'un moteur en choisissant la tension appliquée à ses bornes, que pour des problèmes probabiliste dans un contexte de finance, comme choisir quand acheter ou vendre une action en observant l'évolution de son prix, ou bien un problème d'intelligence artificielle comme choisir la pièce à déplacer lors d'une partie d'échec en observant la position des pièces sur l'échiquier.
On s'intéresse au problème de concevoir une loi de commande, qu'on appellera une politque pour suivre la nomenclature du domaine, qui consiste en une fonction $\pi$ qui détermine l'action $u$ à prendre en fonction de l'état $x$ d'un système observé, et possiblement du temps $t$: \begin{align} u = \pi( x, t ) \end{align} Cette politique va être implémentée dans un agent qui observe l'état $x$ d'un système et agit en conséquence sur ce système pour l'influencer.
Ensuite, la politique sera conçue de sorte à atteindre un objectif qui sera exprimé mathématiquement comme optimiser une fonction objective scalaire, typiquement minimiser un coût ou maximiser une récompense. Pour alléger le texte on parler de coût dans la suite du text. Un point particulier est que la fonction coût est formulée comme une somme de coûts cumulatifs sur une trajectoire du système, avec un coût terminal à la fin de la trajectoire. Par exemple, pour un système dynamique continu, on pourrait caractériser si le système s'est bien comporté en calculant l'intégrale suivante sur une trajectoire: \begin{align} J=\int_0^{t_f}g(x,u,t) dt + h(x_f,t_f) \end{align} où $g$ est un coût cumulatif sur la trajectoire du système, $h$ est un coût terminal et $t_f$ est un horizon de temps. La forme cumulative de la fonction coût est centrale pour utiliser le principe de la programmation dynamique, mais ce n'est pas vraiment restrictif car pratiquement tout les objectifs peuvent être formulés comme la minimisation d'une fonction de coût avec cette forme. Lorsque que notre agent prend les meilleurs décisions possible en fonction de l'objectif on dira que sa loi de commande est optimale au sens qu'elle minimise la fonction de coût.
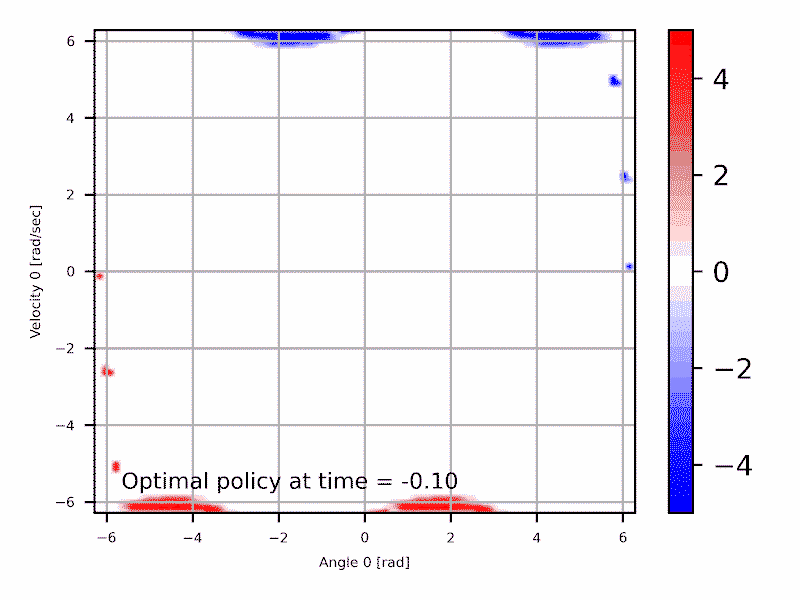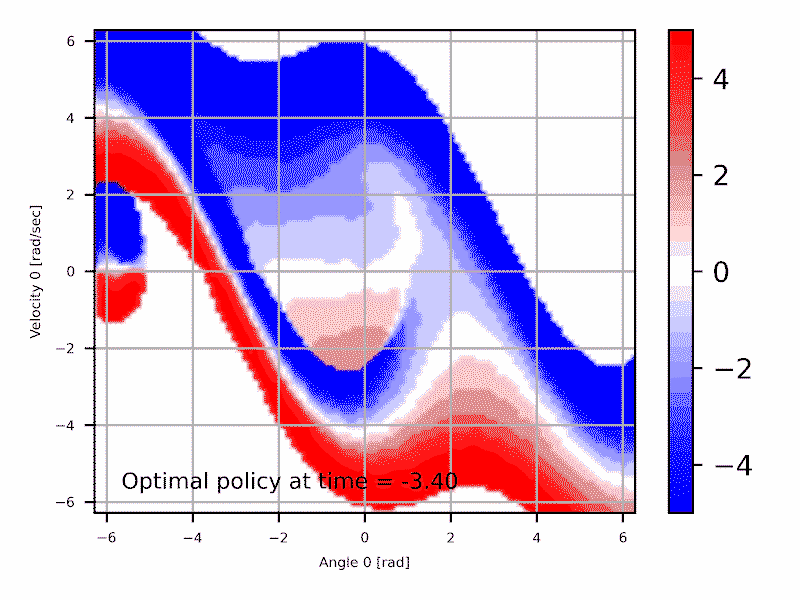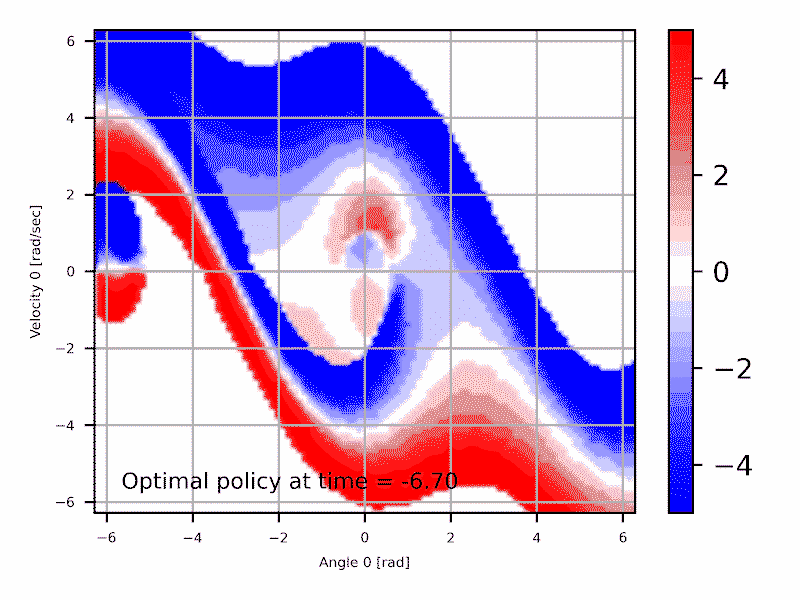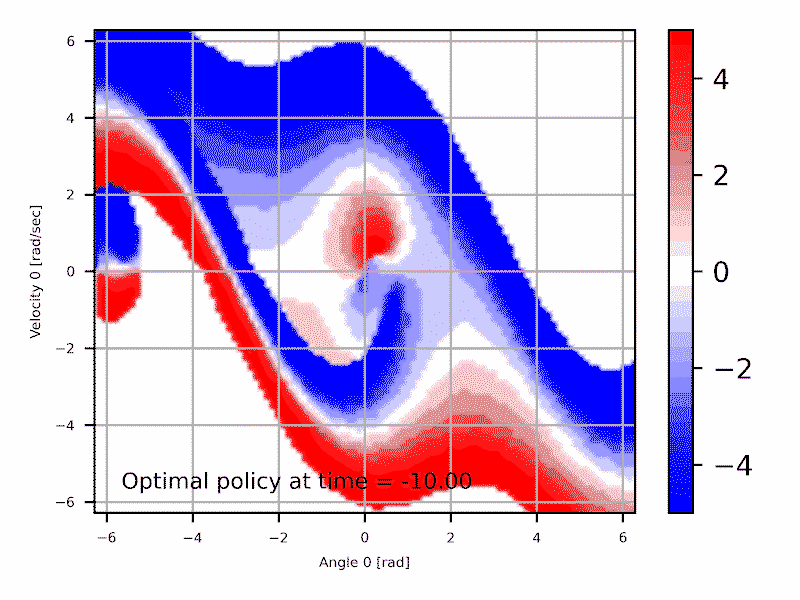
Les deux approches sont équivalentes et interchangeables: \begin{align} \min_{x} f(x) = - \max_{x}{(-f(x))} \end{align} Typiquement le domaine de la commande optimale utilise la formulation de minimiser un coût, qui est souvent relié à l'erreur par rapport à une trajectoire cible. Alternativement, le domaine de l'apprentissage par renforcement préfère optimiser une récompense, qui est souvent par exemple le pointage dans un jeux pour lequel une IA est développé.
Un exemple d'asservissement classique serait un bras robotique où l'action $u$ déterminée par la loi de commande correspond à un vecteur de couples à appliquer dans les moteurs électriques. Cette action sera calculée en fonction de l'état actuel du robot, donc ici un vecteur de positions et vitesses de ses diverses articulations. L'objectif serait formulé comme la minimisation de l'erreur de position du robot par rapport à une position cible et potentiellement d'une pénalité pour utiliser beaucoup d'énergie. Typiquement notre solution de loi de commande serait ici une équation analytique.
Un exemple de prise de décision à plus haut niveau serait de choisir un trajet sur une carte. La loi de commande déterminerait ici quelle direction prendre en fonction de la position actuelle sur la carte. L'objectif d'atteindre la destination le plus rapidement possible pourrait être formuler comme la minimisation du temps écoulé avant d'atteindre celle-ci. La loi de commande (qui serait une solution globale) pourrait être sous la forme d'une table de correspondance où est en mémoire la direction optimale à prendre pour chaque intersection sur laquelle on peut se trouver sur la carte.
Un exemple dans un tout autre contexte serait pour un algorithme d'investissement. L'action de la loi de commande serait ici d'acheter ou non une action en fonction d'une observation de son prix. L'objectif pourrait ici être formuler comme la maximisation des gains financiers. La loi de commande serait ici un seuil de prix, qui pourrait varier en fonction du temps, en dessous duquel l'agent décide d'acheter l'action.
La plupart des outils pour travailler avec ce genre de problèmes sont mieux adapté à une approche de type temps discret. Ces notes vont donc présenter les principes et les algorithmes d'abord avec une approche à temps discret ou un index $k$ indique l'étape actuelle. Il est possible de convertir une problème à temps continu en problème à temps discret en introduisant un pas de temps $dt$ et en considérant que les décisions sont prises en séquence à chaque période de temps $dt$. Alternativement, une approche pour travailler directement en temps continue est présentée à la section \ref{sec:dp_cont}. De plus, pour plusieurs types de problèmes la nature de l'évolution du système est discrètes, par exemple une partie d'échec. La formulation des problèmes en temps discret est donc très générale et s'applique a un grand nombre de problèmes. Le problème équivalent à résoudre en temps discret est de déterminer les lois de commande $\pi_k$, qui dictent l'action $u$ à prendre lorsque l'état du système est de $x$ à l'étape $k$: \begin{align} u_k = \pi_k( x_k ) \end{align} de sorte à minimiser un coût additif de la forme: \begin{align} J = \sum_{k=0}^{N-1} g_k(x_k, u_k) + g_N( x_N ) \end{align} où $N$ est l'horizon qui représente ici un nombre d'étape. De plus ici l'évolution du système est représentée par une équation de différence: \begin{align} x_{k+1} = f_k( x_k, u_k) \end{align} Si on reforme tout le problème en une seule équation mathématique: \begin{align} J^*(x_0) = \min_{c_0, ... c_k, ... c_{N-1}} \left[ \sum_{k=0}^{N-1} g_k(x_k, u_k) + g_N( x_N ) \right] \quad \text{avec} \quad x_{k+1} = f_k( x_k, c_k(x_k) ) \end{align} on cherche les fonctions $c_k$, i.e. les loi de commandes, qui vont minimiser le coût cumulatif sur la trajectoire du système, avec l'évolution qui est définit par une dynamique $f_k$ et les lois de commandes $c_k$.
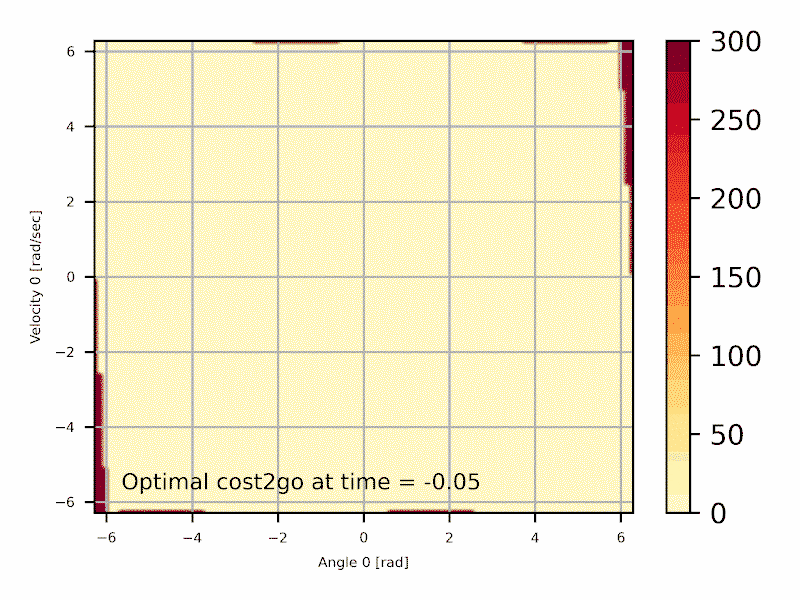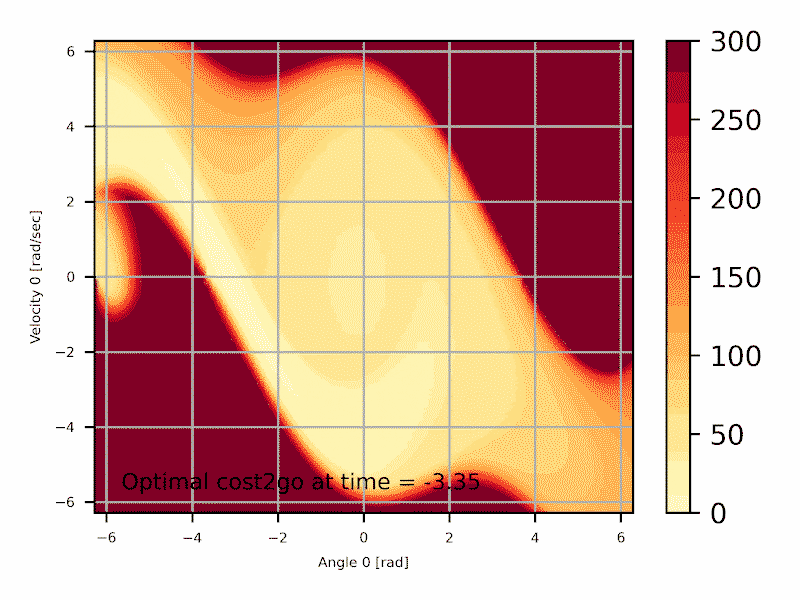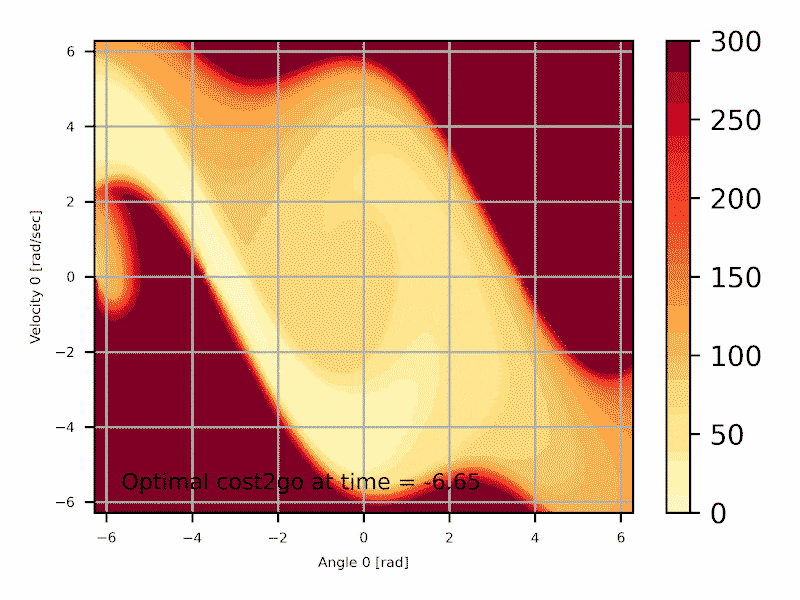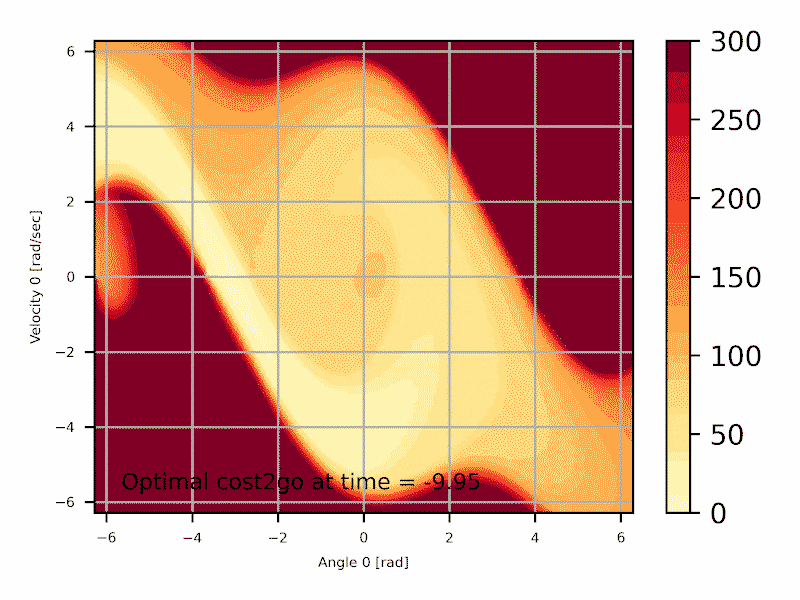
\begin{align} J^*_N(x_N) &= g_N(x_N) \\ J^*_k(x_k) &= \min_{u_k \in U_k(x_k)} \left[ g_k(x_k , u_k ) + J^*_{k+1}( \underbrace{ f_k(x_k , u_k ) }_{x_{k+1}} ) \right] \\ c^*_k(x_k) &= arg\min_{u_k\in U_k(x_k)} \left[ g_k(x_k , u_k ) + J^*_{k+1}( \underbrace{ f_k(x_k , u_k ) }_{x_{k+1}} ) \right] \label{eq:exactdp} \end{align}